Projet cluster de calcul RaspberryPI
Réalisation d’un cluster de calcul à échelle réduite
Les architectures des mésocentres regorgent de technologies toutes plus intéressantes les unes que les autres : redondance des systèmes électrique, informatique ou thermique - protection contre les menaces extérieures physiques comme numérique, distribution des charges de calcul, déploiements automatisés, … Difficile de ne pas être impressionné par tous les défis que les mésocentres doivent relever au quotidien ! Au Club Info, sous l’impulsion de Thomas qui est ingénieur réseau à la DSI de l’UCA (c’est lui qui est aux manettes de l’usine Gitlab dans le département), nous nous sommes mis au défi de reproduire à échelle réduite un petit cluster de calcul.

Cahier des charges
Après avoir parcouru quelques-unes des responsabilités d’un centre de calcul, il n’est pas évident de savoir par où commencer et quels objectifs se donner concrètement. En se basant sur l’expérience qu’a Thomas de ces systèmes, nous arrivons au cahier des charges suivant :
1) Réseau : pas besoin de partir sur des architectures réseaux avancées, on se reposera ici sur un simple routeur managé 10Gb/s afin de gérer l’ensemble du trafic réseau.
2) Matériel de calcul : là encore on imagine difficilement arriver à nos fins à l’aide de matériel professionnel, on agrégera donc dix Raspberry Pi pour émuler notre noeud de calcul. Ces petits ordinateurs ont l’avantage d’être très performants si l’on considère leur taille et leur prix (pour environ 50€ pièce, on obtient un Cortex-A53 qui tourne à 1.4GHz, 1Gb de RAM, …). Nous travaillerons évidemment sur une Debian pour arriver à nos fins :)

3) Un ordonnanceur open-source, SLURM, qui s’adapte à toutes les tailles de cluster lorsque l’on souhaite faire de la distribution de charge de calcul.
4) Un système de monitoring, ici Ganglia, lui aussi populaire, open-source et scalable, qui nous permettra de garder un oeil sur nos systèmes.
5) Un programme à exécuter de manière distribuée ! On cherchera un programme pas trop “malin” qui nous permettra de mettre en avant notre cluster de calcul.
Let’s hack
Pour le programme, pas besoin de casser la baraque, on décide donc de partir sur un petit bruteforceur de mot-de-passe. Voici les principaux critères qui nous ont guidé :
-
Performances : si le programme est trop rapide, l’aspect pédagogique des systèmes distribués sera plus difficile à percevoir ; s’il est trop lent on risque de s’ennuyer. Il a donc fallu adapter l’algorithme de notre petit programme, qui finallement ne bruteforcera que des mots-de-passe alphabétiques allant de quatre à six caractères en jouant sur les caractères ASCII pour parcourir les différentes combinaisons possibles.
-
Distribuabilité : comme notre programme ne teste que des portions déterminées de combinaisons, on peut découper notre problème en presque 600 tâches : “aa”, “ab”, “ac”, … C’est ridicule, mais ça répond à notre besoin tout en métant l’emphase sur “diviser pour mieux reigner”.
-
Simplicité : ici la vedette c’est le système distribué, on ne voulait pas concentrer le gros des explications sur le programme. D’ailleurs, notre système de résolution n’utilisera pas mécanismes “poussés” comme du chiffrement asymétrique. Nous nous contenterons de donner naïvement le mot-de-passe aux noeuds qui vérifieront si la chaîne qu’ils ont trouvée correspond à celle attendue.
Au travail !
Si ce projet regorge à mon sens de détails intéressants, je vais m’atteler à résumer les grandes étapes de ce projet ; l’idée c’est de comprendre les étapes qui ont été nécessaires pour réaliser ce projet et d’en ressortir avec quelques notions :)
Réseau
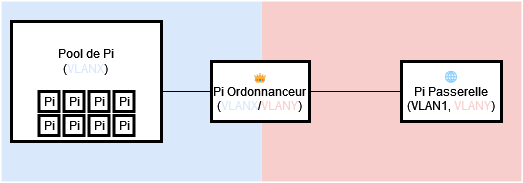
Notre réseau peut se résumer à trois grands acteurs : la pool de Raspberry Pi, qui aura pour mission de faire fonctionner notre petit programme lorsque l’on lui demandera ; un ordonnanceur - dont on reparlera plus tard - qui va nous permettre d’orchestrer nos Pi (quand, quoi et comment exécuter le programme) ; et enfin une passerelle, afin de faire le lien avec l’extérieur. Pour faire les choses proprement, on choisit de cloisonner nos acteurs par responsabilité : la pool d’une part, de l’autre l’extérieur et entre-deux l’ordonnanceur qui vient faire le pont. On se sert des VLAN, pilotés par notre switch managé, pour matérialiser notre architecture dans le réseau.
Ansible
Configurer une machine à la main est un travail laborieux, méticuleux et prône aux erreurs de répétition. Pour remédier à cela, des outils comme Ansible proposent d’automatiser le déploiement de configurations - aussi appelées “recettes” - sur les machines que l’on souhaite asservir. Par l’intermédiaire de fichiers au format YAML, nous avons la possibilité d’expliquer à Ansible à quoi doivent ressembler nos configurations modèles et sur quelles machines elles doivent être appliquées.
Exemple d’une étape de mise à jour du fichier hosts partagé par toutes les machines (on copie un hosts modèle sur la machine cible) :
- name: "Update hosts file"
template:
src: resources/etc/hosts
dest: /etc/hosts
tags: hosts
En plus d’appliquer nos configurations, Ansible permet également :
- de vérifier la conformité d’une machine par rapport aux recettes qui la concerne, tout cela de manière intelligente puisque les règles ne sont appliquées qu’au besoin ;
- d’ajouter de nouvelles machines de manière triviale : Ansible n’a pas besoin d’un client dédié, il lui suffit d’avoir un accès SSH pour travailler
Sans aller chercher les fonctionnalités avancées de l’outil, nous pouvons dès lors développer une recette assez généreuse qui viendra configurer en un éclair nos nouvelles machines. La seule intervention nécessaire est celle demandant de générer une image Debian avec un compte root ayant explicitement autorisé notre ordonnanceur à se connecter. La procédure ne se résume plus qu’à flasher la carte SD d’une Pi, ajouter son IP à notre fichier hosts et il ne reste plus qu’à lancer Ansible !!
SLURM
SLURM, l’élément coeur de notre système, est un ordonnanceur. Au même titre que celui qui est utilisé par un système d’exploitation, son rôle est d’assigner les ressources disponibles aux tâches qui lui sont confiées. Libre à lui ensuite “d’ordonner”, c’est-à-dire d’appliquer des stratégies d’optimisation ou non sur ces opérations (priorisation de tâches, noeuds attribués, algorithmes de distribution, …). Dans le cadre de notre architecture, nous allouons huit Raspberry Pi au calcul pur - ce sont des noeuds. Pour piloter ces noeuds, nous dédions une Pi entière que nous appellerons simplement “l’ordonnanceur”. Du point de vue de SLURM, l’ordonnanceur est le serveur et les noeuds les clients.
Pour s’intercaler avec notre petit programme, nous utilisons un mode très simple de SLURM qui nous permet de travailler avec des hooks sous forme de scripts :
- prolog.sh : il est appelé en amont de la tâche
- hack.sh : traite l’exécution de notre petit programme (ce nom n’est pas standard, c’est celui que nous lui avons donné)
- epilog.sh : appelé en fin de traitement de tâches
Voici un schéma simplifiant le mode de fonctionnement de SLURM et la façon dont il s’intercale avec notre petit bruteforceur de mot-de-passe (on distingue également l’interface web dont nous discuterons un peu plus tard) :
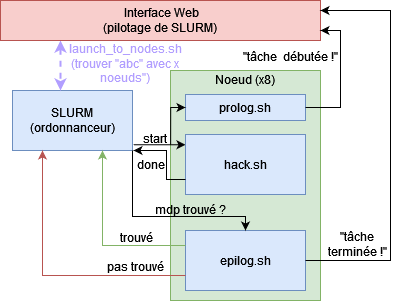
Pour décrire concrètement ce qu’explique ce schéma :
1) L’utilisateur configure le mot-de-passe à trouver, spécifie le nombre de noeuds qui seront utilisés et valide son entrée
2) SLURM génère alors les quelques 676 tâches (aa, ab, ac, …) et commence à les distribuer sur les noeuds attribués par l’utilisateur
3) Avant l’exécution de chaque tâche, chaque noeud exécute un script préliminaire, prolog.sh, qui ici permet d’alerter l’interface Web qu’un traitement va débuter
4) Le script principal est exécuté, aka. notre programme
5) Une fois terminé, il prévient l’ordonnanceur qui lui demande d’interpréter les résultats de son traitement par l’intermédiaire du script epilog.sh ; ici : est-ce que le mot-de-passe trouvé correspond à celui recherché ? Si le mot-de-passe a été trouvé, il prévient l’ordonnanceur et l’interface web qu’il n’est plus nécessaire de chercher. Dans le cas contraire, il prévient toujours l’ordonnanceur et l’interface web, mais SLURM continuera à distribuer d’autres tâches aux noeuds ayant terminé leur traitement.
D’autres systèmes périphériques interviennent dans notre configuration, dont un répertoire partagé en NFS de l’ordonnanceur vers les noeuds, mais je décide de ne pas en parler pour ne pas plus allonger cette partie.
Ganglia
Ganglia est un outil de monitoring très puissant et couramment utilisé dans l’industrie. Nous ne l’avons utilisé qu’à un faible pourcentage de ses capacités, mais il nous a rendu de fiers services en nous permettant de contrôler efficacement l’impact de notre programme sur nos cluster de calculs !
Voici un aperçu de ce que le logiciel permet de faire :

Interface web
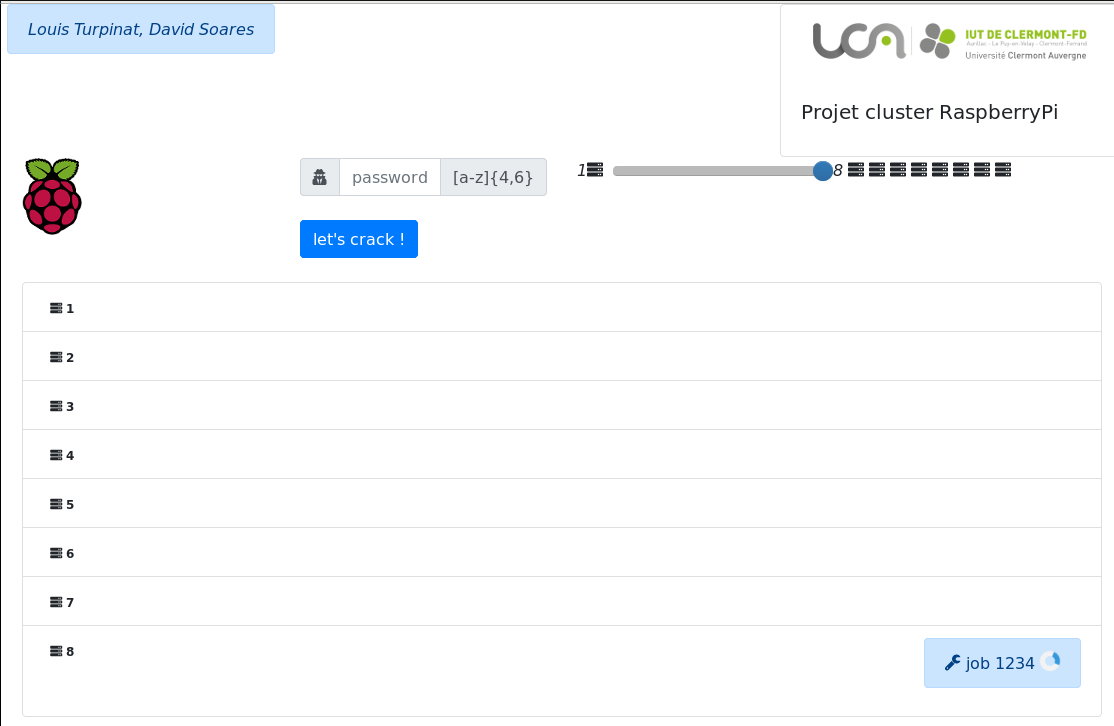
Si une interface en ligne de commande est tout à fait satisfaisante à des fins de prototypage, elle n’est pas malheureusement pas très adaptée lorsque l’on souhaite présenter notre projet à d’autres personnes. L’un des objectifs ayant été pour nous de présenter le cluster aux portes ouvertes de l’IUT informatique d’Aubière, nous avons décidé de mette sur pied avec Thomas une interface web permettant de s’interfacer avec SLURM. Cette interface développée en GO permet en quelques cliques de saisir un mot-de-passe, allouer un certain nombre de noeuds (entre un et huit), consulter en direct la liste de tâches attribuées par l’ordonanceur et le moment où celles-ci sont traitées. Ce qu’il est intéressant de remarquer est la façon dont les tâches se répartissent et l’impact que le nombre de noeuds attribués a sur les performances de l’objectif principal, à savoir “hacker” un mot-de-passe.
L’équipe et conclusion
Ce projet a été rendu possible grâce à l’implication très forte de Thomas dans ce projet, notamment pour la réalisation de l’interface web : merci à lui ! Merci également à Marc pour son soutien. Enfin un remerciement à David qui a réalisé entièrement le programme de bruteforcing. Pour ma part (Louis), j’ai eu la chance de pouvoir travailler de manière transversale sur tout l’admin-sys du cluster, c’était passionnant !
La réalisation de ce cluster a été une opportunité en or qui nous fait beaucoup apprendre tout en permettant aux non aficionados d’en comprendre le principe général grâce à l’interface.
Dans cet article, j’ai essayé de ne pas trop rentrer dans les détails : inutile de réaliser une série, mais je vous propose bien sûr d’aller consulter le code source du projet sur Github !